(Originally posted in Bitcoin Magazine)
This rather long meme, which has been circulating lately, makes fun of the views of Bitcoin supporters by listing commonly made statements and contrasting them with contradicting statements or developments.
This was obviously intended for humorous purposes, and as such, I should probably not take it too seriously.
But as the titular proverb goes, there is a grain of truth in every joke, and the existence of this image sheds light on what some people think. I found here an instructive opportunity to dissect the arguments and share my thoughts on them.
“Peer-to-peer electronic cash” vs. “Pushing people to spend is a scam”
The former is in the title of Bitcoin’s white paper; the latter appeared in a presentation by Giacomo Zucco.
This a contentious issue in the Bitcoin community. I am of the opinion that spending Bitcoin is extremely important and should be encouraged. Others think it is unnecessary — or worse.
So in a way, I kind of agree with the image creator here.
However, one argument in favor of the latter statement is that the key word is not “spend” but rather “pushing.” Even if spending Bitcoin is great, people should be free to do whatever they want, and pushing people to do anything could be frowned upon.
“In BTC bugs like this ‘never’ make it to production” vs. “CVE-2018-17144 is the biggest bug to date”
Never say never. Where there’s smoke there’s fire, and where there’s code there are bugs. It should be obvious that anyone who said that critical bugs can never make it to production in Bitcoin was overly enthusiastic.
The only thing we can do is have a rigorous development and testing process that seeks to minimize the occurrence of critical bugs and to deal with such bugs effectively once they are discovered.
The fact that we haven’t had a bug like this in the past five or eight or 10 years (opinions vary) speaks volumes about the effectiveness of this effort.
To drive the point further: The worst bug in the past eight years is one that was fixed before it managed to have any effect at all. This can be seen as a positive sign, and I wish all bugs were as benign.
This argument should not be seen as belittling the severity of CVE-2018-17144. It was very severe: It shouldn’t have happened, the fact that it happened is a failure of the process, it undermines Bitcoin’s path to mainstream adoption, and we should study how it happened and make changes to hopefully prevent bugs as severe from recurring in the future.
“Users have to be free to run the version they want” vs. “Upgrading to 0.16.3 is required”
I think the former statement is inaccurate. The correct statement, of course, is that users can run any version that is compliant with the protocol consensus rules. 0.16.2 is not compliant with the protocol, and thus nobody should run it.
It doesn’t have to be 0.16.3, though. 0.15.2 and 0.14.3 are also compliant, as are versions of separate implementations.
“SegWit is optional, that’s why we made it a soft fork” vs. “Upgrading to 0.16.3 is required”
I think the former statement mixes up a few notions.
Usage of SegWit transactions is optional. Someone who doesn’t want to use this new feature can continue using Bitcoin just as she has so far. This is in contrast to changes that could modify or invalidate existing usage practices.
Compliance with the protocol rules that make up SegWit is not really optional. They are part of the consensus rules, and all nodes should be compliant. The fact that it’s a soft fork doesn’t change that.
What using a soft fork enables is graceful degradation. Using a non-SegWit node is far from ideal, but it does not cause the node to be immediately booted from the network. It can still understand most of what is going on in the network; in particular, those parts that are relevant to it (assuming it uses neither SegWit nor anyone-can-spend opcodes that were commandeered for SegWit).
This does not mean it makes sense for anyone to purposefully handicap themselves and use a version that specifically does not understand the entirety of the consensus rules.
But if one insists … I guess he can also run pre-SegWit versions (or perhaps a new version that excises SegWit out), as long as they are not affected by CVE-2018-17144.
In addition, there is a big difference between forcing everyone to upgrade just because we want to add a new feature, and forcing everyone to upgrade because we have found a critical security bug.
And the kicker: If we do something like a hard fork, block-size increase, any non-upgraded node will be completely disconnected.
As for CVE-2018-17144: Even though the official requirement is to patch (and you should all do that!) if someone didn’t get the memo and is still running an unpatched version, he should still be fine, as long as he waits for confirmations and almost all other nodes on the network are patched.
“There’s no way to track the growth of LN (privacy!!!)” vs. “Lightning Network is growing strong”
The Lightning Network does have the potential to offer improved privacy over Bitcoin, but there are different levels of privacy. There is complete zero-knowledge where you don’t know anything about what’s going on, other than that it follows the protocol. You can have a system where you know the aggregate total of activity, but you can’t match it to individual transactions or people. You can have a pseudonymous system where you know of all transactions, but the identity of the people involved is obfuscated. And many other variations.
With the standard way of using Lightning, you can know the number of channels and total amount of funds locked in them, but not necessarily the volume of payments done on it. So you can know that it is growing even without knowing a lot about what is going on in it.
Future usage patterns might make tracking growth harder, but not necessarily impossible.
“You need to run your own full node to help secure the network” vs. “The network is safe since all the miners have upgraded”
The former statement is a somewhat contentious topic; but it is important to distinguish what running a node does fo you from what it does for the network.
Running a node helps keep you secure, by guaranteeing that when you receive bitcoins you actually receive bitcoins, and that those bitcoins comply with the protocol you agree with.
As for how it helps the network, I wouldn’t use the word “secure.” What it does is add redundancy to the data and improve connectivity, in order to make it easier for other nodes to access it.
There is also a distinction between systemic and personal risk. If you didn’t upgrade your own node, there is always the chance you will be fooled, but that is your own problem. But if an invalid transaction is being included in a block and accepted by major service providers, that is a risk to the integrity of the currency as a whole, which is much more severe.
Miners have a key role to play here, and, as long as a supermajority of miners are patched, the systemic risk is minimal.
“BTC is secure because it has the most accumulated hashrate” vs. “F*** those selfish egoist miners”
Miners are selfish and egoistic. And they should be. The system is based on an incentive mechanism that lets agents secure the network while seeking their own financial benefits. We should thank the miners for participating in this selfish way.
The only problem is when short-sighted greed causes some miners to act in a way that harms both themselves in the long run and also the network.
Anyway, one of the things that makes Bitcoin secure is indeed the large amounts of hashrate that (selfishly) rallies behind it.
“The ledger is immutable” vs. “In case of exploit the ledger would have been rolled back”
Here we get to the interesting part — which justifies a whole article on its own, so I’ll be brief here.
The meaning of “the ledger is immutable” is that:
- There are protocol rules that dictate which transactions are valid
- The protocol rules will not be changed just for the purpose of invalidating some particular transactions that people don’t like.
But that is not what is happening here. It’s not like someone stole a private key and used it to sign a transaction that is contrary to the wishes of the original owner but is still perfectly protocol compliant … and that we now wish to reverse it.
Instead, we found out that previous software versions failed at enforcing the protocol rules we all thought we were agreeing with. The default course of action (if there are indeed such invalid transactions) would be to simply run a patched version that enforces the rules more rigorously.
The problem is that such a move could basically invalidate all blocks since the first invalid transaction, which would be catastrophic. So it could be appropriate to tweak the consensus rules slightly to handle this move more gracefully.
The significant difference is that we are implementing a systemic protocol change to fix a systemic problem and not a systemic protocol change to fix an individual problem, as we’ve seen in some other cryptocurrencies.
“In Bitcoin code is law” vs. “Bitcoin is a social contract”
The latter statement is more correct.
There is a level in which code is indeed law. As long as everyone agrees on the protocol rules, what matters is the code that runs on every node on the network and mechanically enforces the rules; not any individual deciding which transactions to keep and which to throw away.
But who decides which code to run? Who decides the protocol rules? This is deferred to a higher authority: the social contract between people who use Bitcoin and give it value, known as the economic majority. Bitcoin is what people decide Bitcoin is.
“Bitcoin is valuable because of its network effect” vs. “Reducing total usage is a way to increase full node ratio”
The former statement is true, and we’ll be hard pressed to find anyone who disagrees. Currency is not something you can use by yourself; you can only use it if other people use it as well. So a strong network is necessary for Bitcoin to have value.
As for the latter, I have not previously heard of the concept “full node ratio,” and there is hardly anyone who advocates for “reducing total usage,” so I can’t really comment on that. Indeed, the two statements seem to be at odds, and it is the former which is more sensible.
And as for that guy at the end of the meme who is so stressed out by the decision he has to make …
There’s no need for stress or anxiety. As long as we remember what Bitcoin is, why it’s here, how it works and what the fundamental principles behind it are, we should be able to tackle any challenge that lies ahead.
 or
or  .
. . There are many ways to order it (24, to be exact, if you remember your combinatorics) – for example,
. There are many ways to order it (24, to be exact, if you remember your combinatorics) – for example, 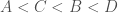 , or
, or  , or
, or 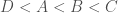 . But all these orderings are fundamentally the same. They all follow the pattern – “One item, then another, then another, then another”. Different orderings have different items in each position, but they all follow the same basic structure. This structure is represented by the ordinal number 4 (so called because it is the only way to order sets of size 4).
. But all these orderings are fundamentally the same. They all follow the pattern – “One item, then another, then another, then another”. Different orderings have different items in each position, but they all follow the same basic structure. This structure is represented by the ordinal number 4 (so called because it is the only way to order sets of size 4). which is differentiable everywhere and satisfies
which is differentiable everywhere and satisfies  for every
for every  , and
, and  . You can also use
. You can also use  instead of
instead of  ).
).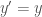 . As such, it is a building block for solutions to differential equations of all kinds.
. As such, it is a building block for solutions to differential equations of all kinds.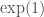 ? This is useful, because one of the properties of exp (which we can prove using the definition we started with) is that
? This is useful, because one of the properties of exp (which we can prove using the definition we started with) is that  . Using this, we can show that
. Using this, we can show that 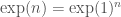 for every integer
for every integer  (where taking a power is a simple repeated multiplication). In other words, knowing the value of the function at 1 allows us to find its value for every integer. So we give the value of
(where taking a power is a simple repeated multiplication). In other words, knowing the value of the function at 1 allows us to find its value for every integer. So we give the value of  , we have
, we have  , not just for integer
, not just for integer 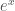 instead of
instead of 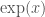 .
.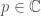 such that for every
such that for every  , we have
, we have  (which is the smallest with this property). This number happens to be purely imaginary, so if we divide it by
(which is the smallest with this property). This number happens to be purely imaginary, so if we divide it by 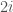 , we get a real number. This real number is what we call π.
, we get a real number. This real number is what we call π.![The Blind Men and the Elephant. [the BIG picture] | by Sophia Tepe ...](https://fieryspinningsword.com/wp-content/uploads/2020/07/cdda6-1-fxkvfupjw6oudlto3czha.jpeg)
